About
Krake is an orchestrator engine for containerised and virtualised workloads across distributed and heterogeneous cloud platforms. It creates a thin layer of aggregation on top of the different platforms (e.g. Kubernetes) and presents them through a single interface to the cloud user. The user's workloads are scheduled depending on both user requirements (hardware, latencies) and platform characteristics (energy efficiency, load). Krake can be leveraged for a wide range of application scenarios such as the central management of distributed compute capacities as well as application management in Edge Cloud infrastructures.
Open source / proprietary
Open Source, Apache 2.0 Licence
Architecture
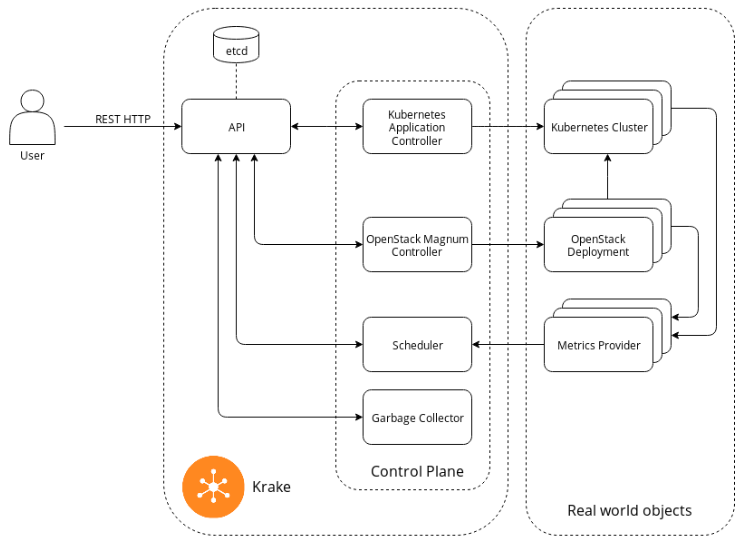
The components in the architecture of Krake are loosely coupled and therefore can be exchanged, altered or extended with new components.
The control Plane is in continuous exchange with Krake’s API and real-world objects and therefore continuously manages all real-world objects registered as resources in Krake. Real world objects are defined as different instances like Kubernetes clusters or Metrics Providers like Prometheus.
The Kubernetes Application Controller of Krake manages containerised applications migrated to Kubernetes clusters. These clusters need to be registered in Krake. Label constraints are given by the Krake API or custom metrics distributed through the Metrics Providers. The scheduler watches and evaluates these indicators and decides which Kubernetes cluster is the best fit to run the application on. To run an application, it needs to be containerised and published on a reachable registry, e.g. Docker Hub. This app can be deployed by Krake with a manifest file. In this file, the image of the containerised application is linked, along with other settings.
The image below shows the overall architecture of Krake: